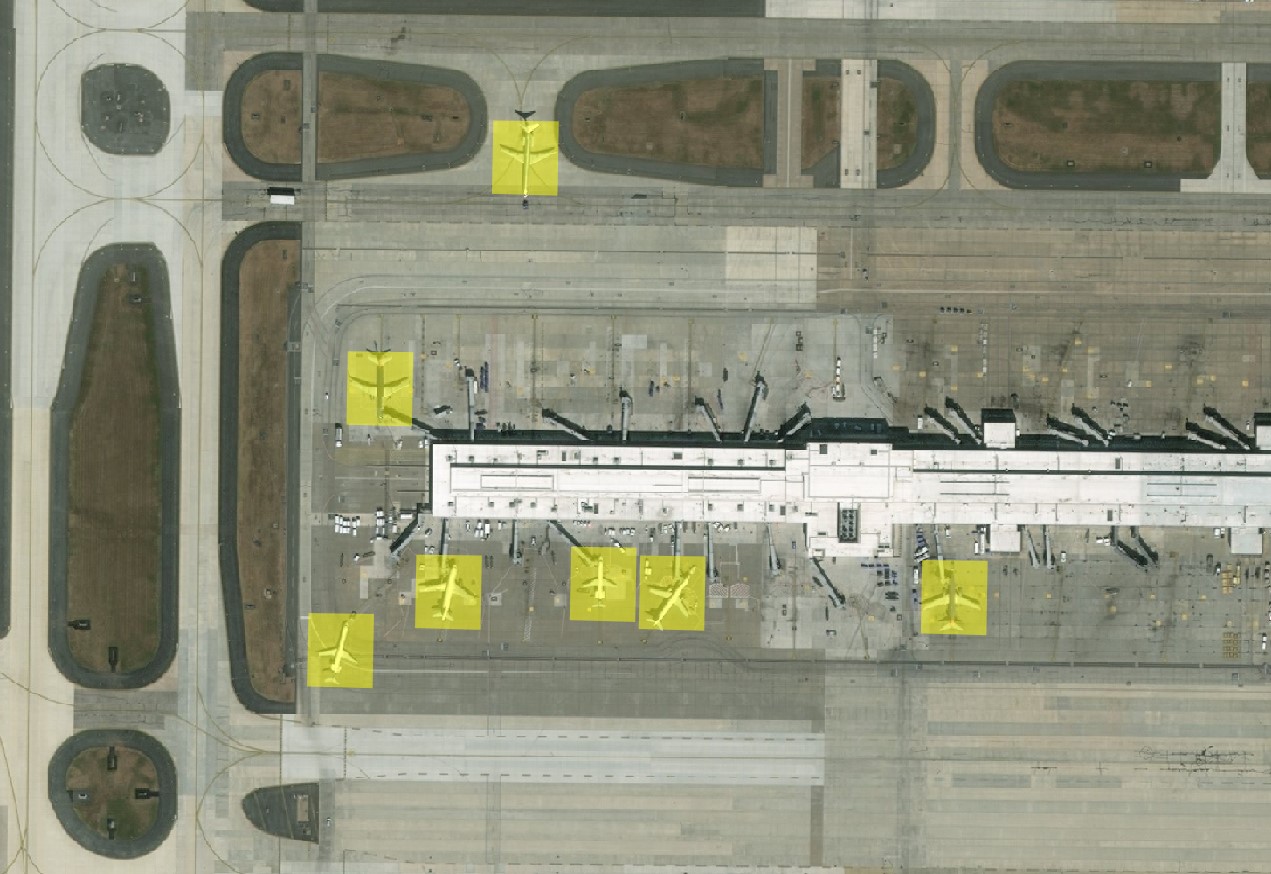
 Object recognition results from our deep learning software.[/caption]
DigitalGlobe’s satellite constellation collects approximately 4 million km2 of high-resolution earth imagery each day, yielding massive amounts of information about our changing planet. To gain insight about important activities taking place around the globe and narrow the search space—finding what is meaningful—we rely on computers to identify objects and patterns automatically in our data.
And we also rely on the latest and greatest—technologies, developers and ecosystem partners—to find new, faster, better ways to analyze and use our massive trove of Big Data. DigitalGlobe’s Geospatial Big Data (GBDX) platform provides cloud-based access to our imagery (current and historical), as well as access to the tools and algorithms to extract meaningful data. GBDX makes it easy to search, explore and order from the vast archive, and enables developers and analysts to apply their own algorithms to our imagery at scale. With GBDX, users can apply workflows easily to enrich imagery with capabilities, like atmospheric compensation and micro-tiling to facilitate distributed analytics. The platform also has crowdsourcing capabilities to rapidly discover and validate objects in our imagery to expedite algorithm validation and training.
Object recognition results from our deep learning software.[/caption]
DigitalGlobe’s satellite constellation collects approximately 4 million km2 of high-resolution earth imagery each day, yielding massive amounts of information about our changing planet. To gain insight about important activities taking place around the globe and narrow the search space—finding what is meaningful—we rely on computers to identify objects and patterns automatically in our data.
And we also rely on the latest and greatest—technologies, developers and ecosystem partners—to find new, faster, better ways to analyze and use our massive trove of Big Data. DigitalGlobe’s Geospatial Big Data (GBDX) platform provides cloud-based access to our imagery (current and historical), as well as access to the tools and algorithms to extract meaningful data. GBDX makes it easy to search, explore and order from the vast archive, and enables developers and analysts to apply their own algorithms to our imagery at scale. With GBDX, users can apply workflows easily to enrich imagery with capabilities, like atmospheric compensation and micro-tiling to facilitate distributed analytics. The platform also has crowdsourcing capabilities to rapidly discover and validate objects in our imagery to expedite algorithm validation and training.
 Our goal is to make it easy for developers and data scientists to use Hadoop (named by founder Doug Cutting after his son’s yellow toy elephant) and other modern frameworks, like Spark, to apply and validate novel analytic algorithms against our imagery at scale.
Our MapReduce for Geospatial (MrGEO) project, leverages the power of cloud computing to process global raster data sets (e.g., imagery and terrain) in a fraction of the time it takes to perform similar operations on the desktop. The idea is simple: Spin up a cluster of machines to distribute geospatial data in the cloud and bring your algorithm to the data. The results of the distributed algorithms are combined in the cloud and moved to the desktop for final analysis. This has always been a win for our customers and us as a way to process large volumes of data.
Now we’re exploring the potential of a branch of artificial intelligence called deep learning to automate object detection and analyze big data. While distributed processing provides a means of keeping pace with the massive volumes of imagery we collect each day, training algorithms to detect objects like airplanes, vehicles and even elephants (the gray ones) require massive amounts of processing to be effective. In our research, we saw impressive results through the application of deep learning, which has been applied to image and video classification through open source frameworks like Theano, Torch and Caffe. Internet giants Google and Microsoft even released their own tools for deep learning—TensorFlow and CNTK—both intended to lower the barrier of entry to this flavor of AI.
Our goal is to make it easy for developers and data scientists to use Hadoop (named by founder Doug Cutting after his son’s yellow toy elephant) and other modern frameworks, like Spark, to apply and validate novel analytic algorithms against our imagery at scale.
Our MapReduce for Geospatial (MrGEO) project, leverages the power of cloud computing to process global raster data sets (e.g., imagery and terrain) in a fraction of the time it takes to perform similar operations on the desktop. The idea is simple: Spin up a cluster of machines to distribute geospatial data in the cloud and bring your algorithm to the data. The results of the distributed algorithms are combined in the cloud and moved to the desktop for final analysis. This has always been a win for our customers and us as a way to process large volumes of data.
Now we’re exploring the potential of a branch of artificial intelligence called deep learning to automate object detection and analyze big data. While distributed processing provides a means of keeping pace with the massive volumes of imagery we collect each day, training algorithms to detect objects like airplanes, vehicles and even elephants (the gray ones) require massive amounts of processing to be effective. In our research, we saw impressive results through the application of deep learning, which has been applied to image and video classification through open source frameworks like Theano, Torch and Caffe. Internet giants Google and Microsoft even released their own tools for deep learning—TensorFlow and CNTK—both intended to lower the barrier of entry to this flavor of AI.
 However, the power of this technology can only be achieved through high-performance GPU architectures, like those made by NVIDIA, which have become today’s standard for deep learning computing. NVIDIA has not only innovated at the hardware level, it has built an ecosystem around deep learning that has democratized the technology for the masses (e.g., DIGITS). Every year developers and scientists are winning contests, such as ImageNet, by building deep learning algorithms on NVIDIA GPUs.
We’re experimenting with how deep learning can be used to find objects in our satellite imagery and other massive data sources, like social media. The results have been very promising. Our models can reliably discover dozens of object types. We are now exploring a series of hybrid architectures to combine the scalability of distributed image processing and the unique capabilities of high-performance computing. We leverage NVIDIA GPUs to train our deep learning models and are then able to apply those models against data at scale in a distributed Amazon Web Services (AWS) cloud environment. This hybrid architecture can enable a whole-new class of mission where we need to search massive amounts of information quickly to narrow the search space. For example, we can use this method to identify the migration patterns of actual elephants in Eastern Africa to provide intelligence to thwart illicit wildlife trafficking.
Imagine using this method to detect interesting objects and activities automatically across every image DigitalGlobe collects (even back in time through our 70 petabyte archive). Furthermore, imagine applying this capability to other sources of imagery collected by satellites, UAVs or even mobile phones. GBDX focuses on solving these classes of problems by making it easy to exploit petabytes of DigitalGlobe imagery and other sources of geospatial data in the cloud, leveraging NVIDIA GPUs to train deep learning algorithms applied at scale using GPU as well as CPU elastic compute.
Any rock star developers or ecosystem partners out there excited to join this journey with us? Do you want to apply big data analytics to make a difference in the world? If so, please contact us at Adam.Estrada@digitalglobe.com.
.
However, the power of this technology can only be achieved through high-performance GPU architectures, like those made by NVIDIA, which have become today’s standard for deep learning computing. NVIDIA has not only innovated at the hardware level, it has built an ecosystem around deep learning that has democratized the technology for the masses (e.g., DIGITS). Every year developers and scientists are winning contests, such as ImageNet, by building deep learning algorithms on NVIDIA GPUs.
We’re experimenting with how deep learning can be used to find objects in our satellite imagery and other massive data sources, like social media. The results have been very promising. Our models can reliably discover dozens of object types. We are now exploring a series of hybrid architectures to combine the scalability of distributed image processing and the unique capabilities of high-performance computing. We leverage NVIDIA GPUs to train our deep learning models and are then able to apply those models against data at scale in a distributed Amazon Web Services (AWS) cloud environment. This hybrid architecture can enable a whole-new class of mission where we need to search massive amounts of information quickly to narrow the search space. For example, we can use this method to identify the migration patterns of actual elephants in Eastern Africa to provide intelligence to thwart illicit wildlife trafficking.
Imagine using this method to detect interesting objects and activities automatically across every image DigitalGlobe collects (even back in time through our 70 petabyte archive). Furthermore, imagine applying this capability to other sources of imagery collected by satellites, UAVs or even mobile phones. GBDX focuses on solving these classes of problems by making it easy to exploit petabytes of DigitalGlobe imagery and other sources of geospatial data in the cloud, leveraging NVIDIA GPUs to train deep learning algorithms applied at scale using GPU as well as CPU elastic compute.
Any rock star developers or ecosystem partners out there excited to join this journey with us? Do you want to apply big data analytics to make a difference in the world? If so, please contact us at Adam.Estrada@digitalglobe.com.
.